This is not a Zen riddle, but the most succinctly provocative way to summarize two parallel strands of audio research that have quietly persisted over about half a century. Moreover, both these strands promise evidence-based improvements to both tonal and spatial reproduction of sound. Both assertions cannot be simultaneously correct, it seems. As far as we know, this is the very first article series targeted at the layman to identify, explain and reconcile it. Understanding the premises and milestones of this curious research tradition is important because it provides a powerful lens to understand its most famous product of late: the Harman curve.
A Quick Rundown of How the Series Is Split
Part 1 <- You are here
The first part of this series will first explain the fundamental, shared principles of human hearing all these approaches are derived from.
Part 2
Go to Part 2
The second installment examines various technologies that have been developed in response to these insights for both loudspeakers and speakers. Tracing the lineage from which the Harman curve descends helps clarify its relative position in this technological landscape. Thus, we can compare Harman curves (because several variants were developed and refined for different applications) to both alternative listening curves and processing techniques in the third part. Curves covered include the highly-abstracted diffuse and free-field curves, and more niche derivatives of both by Sonarworks, Waves NX, Etymotic, Siegfried Linkwitz, and David Griesinger. We will talk about comparison to alternative playback processing techniques includes:
crosstalk cancellation head-related transfer function (HRTF) synthesis crossfeed
Part 3
Go to Part 3
This third part will also allow us to distinguish what is left beyond the Harman target curve for headphones and in-ear monitors (which each have their own respective curves). The choice of corrective processing strongly depends on:
recording and mastering techniques (such as microphone placement and panning), the type of headphone used the anatomy of the individual.
Moreover, the wavelengths of the high frequencies involved in HRTF synthesis and correction are very small. This entails significant sensitivity to variations in headphone placement with each wear, and even within the same listening session as position subtly shifts. It is a complex and dynamic problem. Any further improvements are inconvenient while yielding an uncertain payoff. Much more transparency on the part of studios and sound engineers for their choices, as well as painstaking listener experimentation would likely be needed. Hopefully, more knowledge of these issues increases consumer pressure on manufacturers to address these issues and scale their solutions to improve the listening experience, especially on headphones.
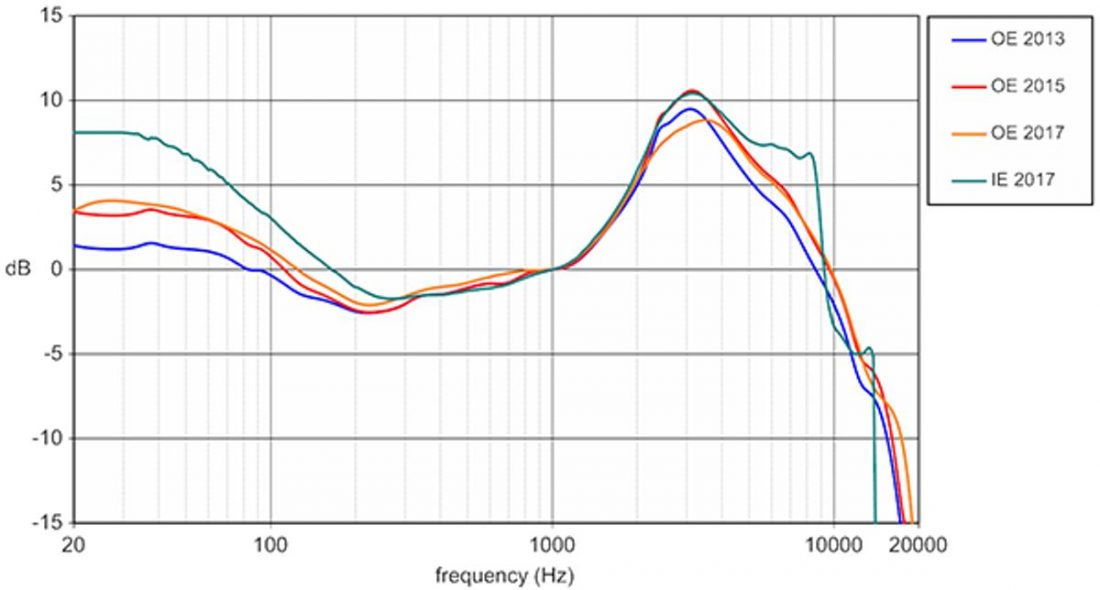
What is the Harman Curve?
Named after the audio equipment manufacturer, Harman, most of its main researchers were affiliated to, the curve entered the spotlight in 2013, after (now-retired) headphone guru Tyll Hertsens of InnerFidelity published a comprehensive feature article summarising the key papers published on the subject. The Harman curve essentially is a target frequency response of what a pair of “good” headphones should exhibit when measured with specialized equipment. The curve is, in fact, a careful balance between individualization and a certain conception of mass appeal, founded on the same psychoacoustic principles that underpin both strands of research. But how was this balance struck, why was it struck, what does it compromise and what does it synergize with? Addressing these questions requires a look at Harman curves, the long (but rewarding) way round. It complements the great articles out there that explain what Harman curves are – a coarse approximation of broadly-agreeable tonality that disregards precise individualization for spatial audio and precise tonality (which are inter-related problems).
Outlining Sound Localization in Human Beings
The first step to understanding Harman curves is to understand the relationship between frequency response (which is what the Harman curves serve as a target of) and human sound localization. Rtings and Wikipedia delve into the subject in more, though still accessible, detail, as does this page by Southampton University. For the purposes of simplicity, here’s the summary. There are four types of cues that dominate directional localization:
Every ear has it own HRTF
Every single ear has its own head-related transfer function (HRTF): changes to the frequency response of external sound sources that our shoulders, torso, head, and ears (both the external pinna and internal canal) cumulatively contribute to as sound from a free-field source bounces off them.
HRTF changes when the direction changes
The HRTF changes as direction changes. We map these changes to a specific direction in our brain when the altered sound hits our eardrums. We have adapted to these changes. Interaural (between two ears) cues assist the HRTF cues. As the two ears are separated by the head, there is a difference in time that the sound reaches, due to the different distance from the source, compounded by the different way sound “wraps” around the head depending on the frequencies excited by the source sound. There is hence also a difference in volume level.
ILD becomes more predominant than ITD at 1kHZ and above
The tradeoff point between which cues become predominant is currently estimated to be around 1kHz, with ITD cues becoming less consistent and precise with placement at high frequencies. This is due to the corresponding wavelength of around 17-18cm at 1kHz, which is the approximate diameter of the human head. As the frequency gets higher and the wavelength gets smaller relative to the head, they are less able to “wrap” around it, giving rise to a significant level difference. Thus, ILD becomes a more predominant cue above around 1kHz, while ITD less so due to its relative instability. Essentially, we triangulate sound through the differences in loudness, phase, and timing between each ear as well.
Broad HRTF features can predict coarse trends
Despite the evident variance in head morphology, there are some broad HRTF features that allow us to determine coarse trends. This concept is crucial to the Harman curve. For instance, a high-level ear canal resonance consistently appears around 3kHz, though the exact center frequency, intensity and Q (technical term for “sharpness” or “narrowness” of the resonance) and shape of the resonance may differ. It is one of the most characteristic features of the HRTF. Tonality and space are related, though not synonymous. Regardless, a prerequisite of accurate spatial reproduction is an individualization of the frequency response, to compensate for the individual differences in the changes induced by the HRTF as the sound hits the eardrum.
What happens if the HRTF is mismatched?
What does a mismatched HRTF entail subjectively? Audiophile label Chesky Records released an extremely well-received binaural album by singer-songwriter Amber Rubarth (“Sessions from the 17th Ward”). One of the songs was “Full Moon in Paris”. However, frontal, external localization with headphones fell grossly short, even with a high-performance Stax earspeaker setup. Ex-Harman Chief Scientist (no relation to the Harman curve research projects), and now independent researcher, David Griesinger, offers this explanation: Yet, even Griesinger’s explanation seemed to be too charitable for what this author experienced. This is likely because this author was of East Asian descent, and his morphology differed enough for HRTFs to diverge even more significantly than Caucasian listeners from the HRTF of the dummy head used. If a visual cue is present at the same time it will almost always dominate the aural cues. With some good showmanship and a subject who is willing to be convinced, these demonstrations can be quite convincing. But with skeptical listening frontal localization of fixed sources is rarely achieved. This meant frontal externalization of the sound was not achieved, let alone precise frontal positioning of the sound sources. Thankfully, work has been done to come up with a standardized dummy head that more closely resembles the broad trends in head morphology of East Asians, which would hopefully close the gap somewhat.
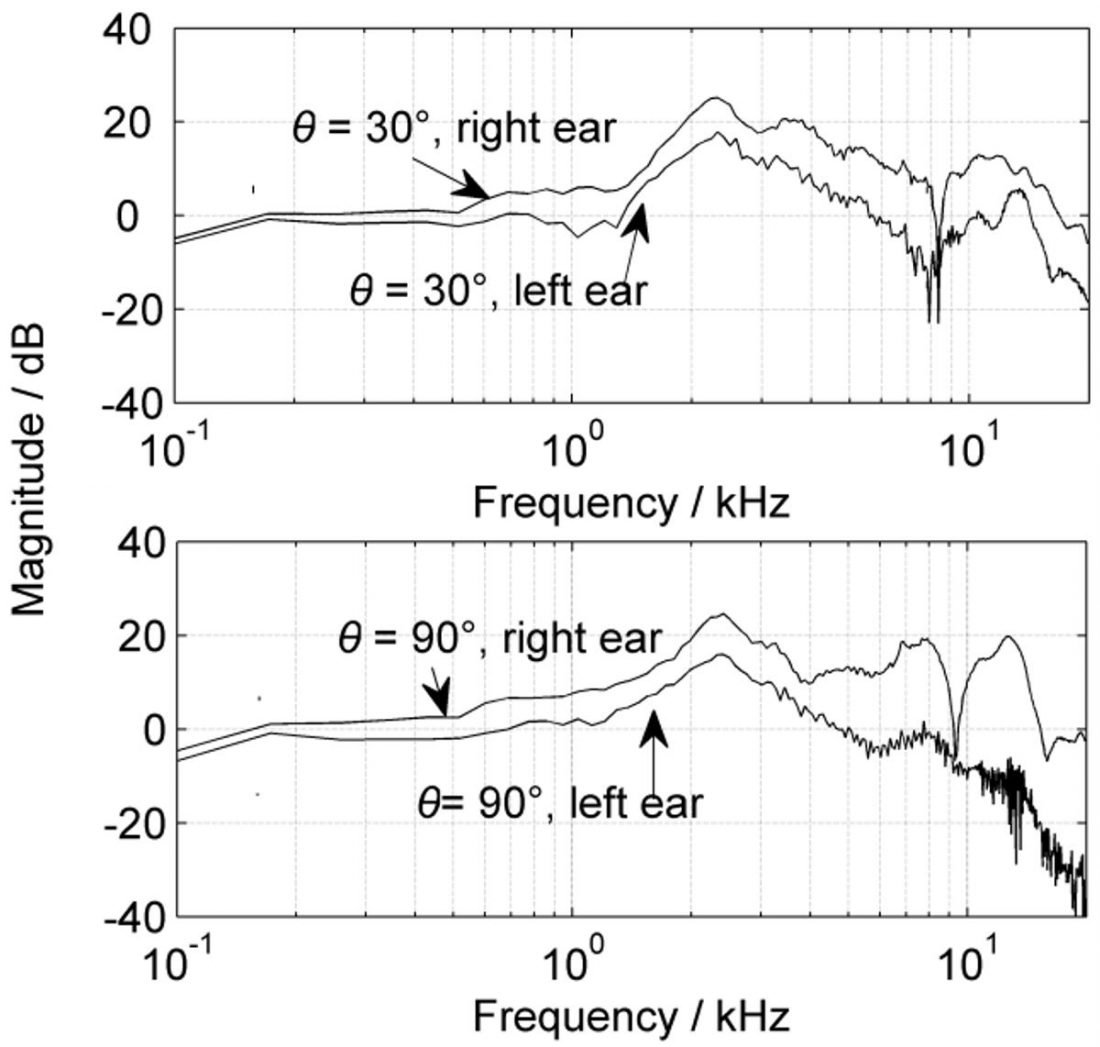
How Sennheiser gets its acclaimed “soundstage”
Headphone design can also help to partially overcome this issue. The Sennheiser HD800(S) is a leading exponent of this approach. Much of its acclaimed “soundstage” can be chalked down to the angled drivers. Angling the drivers causes an approximate HRTF that more closely resembles a frontal HRTF to be generated, rather than a lateral HRTF perpendicular to the ears generated by uncorrected headphone playback. How much does the HRTF there differ? The graphs above, from an excellent open-access chapter on the subject are illustrative. This is the HRTF of an industry-standard head-and-torso-simulator setup, the KEMAR. The top-most curve is the measured HRTF at the right ear from a source placed as if it were the right-channel of a stereo speaker (as well as what is measured at the left ear from such a source). The second-from-bottom curve is what was measured at the right ear from a source perpendicular to it (like a non-angled headphone driver. The notch in HRTF for the perpendicular source is much broader and deeper, spanning from 8 to 10kHz and about 20dB. The 30-degree measurement, which reflects how a loudspeaker or headphone driver angled that way would be perceived, has a much narrower notch (spanning 8 to 9kHz). Even though the notch is about as deep, the overall trend of the curve is much smoother than the perpendicular case. According to Griesinger, his experiments showed also that headphones that lack angled drivers (thus generating this perpendicular HRTF) generate an unnatural sound and make further correction impossible. This is because a perpendicular sound source interacts in a specific way with the ear, yielding a HRTF response that is more audible (as shown above), yet “is impossible to equalize away”. Notches in frequency responses are generally impossible to equalise because they are caused by multiple sound signals cancelling each other out. Boosting the notch merely boosts both signals that cancel each other out. Though HRTFs at other angles will differ, frontal angles clearly have a much less prominent notch. Regardless, due to the relatively unnatural “illumination” of the entire pinna by the radiated wavefront (and hence low fidelity to HRTFs that would generate a natural frontal soundscape), headphone playback (especially of stereo recordings but even for binaural) is intrinsically compromised. That is what RTing’s PRTF measurements measure for – the complete, uniform illumination of the pinna area as if it were from a free-field source. Even the HD800(S) is far from perfect, compared to loudspeakers. The wavefront of speakers in free-field allows for complete pinna illumination (the area over which the pinnae spread is small relative to the area over which speaker radiation is essentially uniform). Another more involved way to partially overcome mismatched HRTF is through using dynamic cues, altering the mismatched HRTF with head movement (by tracking the head of the listener through motion tracking technologies such as the Kinect). However, the root issue of tonal inaccuracy relative to the subject’s ears are still preserved. To sum up:
Conclusion
This basic overview of the complex phenomenon that is human hearing allows us to understand how technology has formulated corrective techniques that address excess distortions that come in between our ears and the recording. In Part 2, we will outline these corrective technologies that have been developed, both popular and obscure.
Pin this image to save this article